Personalized cancer treatment can be more effective, less harmful, and ultimately more likely to result in successful outcomes than the traditional treatments. Prognostic gene expression signatures use expression values of multiple genes in a tumor to predict the recurrence risk of cancer, which enables doctors to determine personalized treatment of each cancer patient. Two successful gene signatures are Oncotype DX and MammaPrint, both of which are used in clinical practice for breast cancer patients. A key step in developing these gene signatures is the careful selection of genes that can provide adequate predictive power for cancer prognosis. With the advance of artificial intelligence (AI), we asked two questions: Can we use AI methods to learn better features in the tumor transcriptome to improve prediction accuracy? Is it possible to create a general approach for constructing prognostic models for all types of cancer that does not select genes in an ad hoc manner?
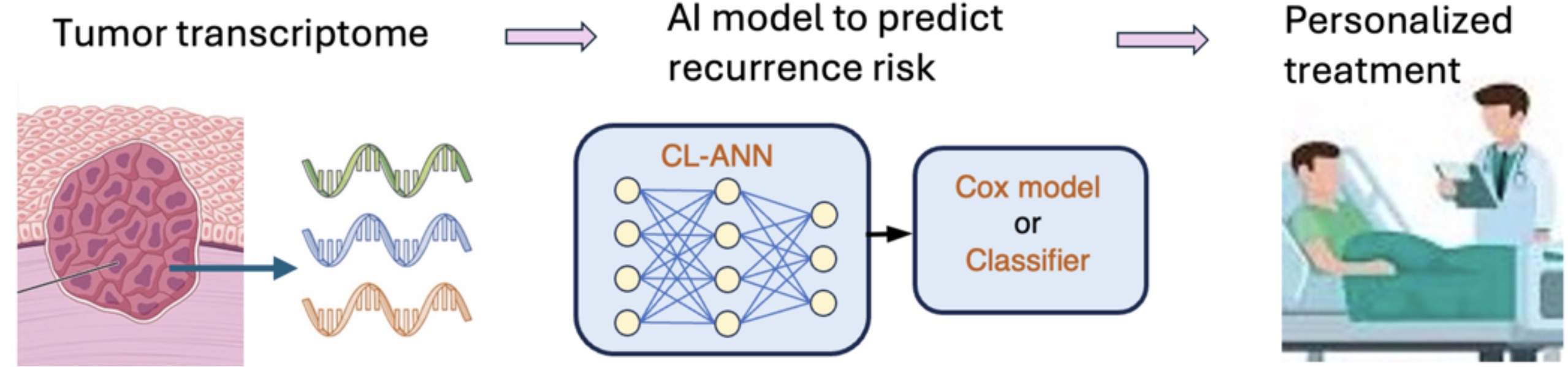
To answer these questions, we adopted a cutting-edge AI technique called contrastive learning (CL), which has recently been shown to significantly improve the accuracy of image classification when compared to other AI methods. Our CL approach first used a deep artificial neural network (ANN) to learn feature representations from cancer transcriptomes. Based on the features from the CL module, we then used the two approaches to predict cancer prognosis. In the first approach, we trained a classifier named XGBoost to categorize cancer patients into a high- or low-risk group of recurrence. This classification approach was also used by MammaPrint. In the second approach, we trained a Cox proportional hazards model to predict the hazards ratio (HR) for cancer prognosis. Similar to the recurrence score (RS) of Oncotype DX, the HR can be used to stratify patients in different prognostic groups.
Using the RNA-seq and clinical of 18 types of cancer from The Cancer Genome Atlas (TCGA), we demonstrated that our CL-based XGBoost classifiers improved the area under the receiver operating characteristic curve (AUC) by over 10% for all 18 types. They achieved an AUC greater than 0.8 for 14 types of cancer, and an AUC greater than 0.9 for 2 types of cancer. Our CL-based Cox models also significantly outperformed the Cox model without CL for 19 types of cancer considered, providing an c-index of about 6% higher on average. We then showed that the HR predicted by our Cox models could effectively stratify patients into distinct groups with varying recurrence probabilities. Moreover, the performance of our CL-based classifiers and Cox models trained with TCGA lung cancer and prostate cancer data were validated with the data from two independent cohorts. Finally, we demonstrated that our CL-based Cox model using the tumor transcriptome can provided significantly better prediction accuracy than the Cox model using the expression values of Oncotype DX genes or the RS score of Oncotype DX, which indicates that our CL-based Cox model can learn better features from the transcriptome, resulting in improved prediction accuracy.
CL-based classifiers for 18 types of cancer and CL-based Cox models for 19 types of cancer, trained with TCGA data, as well as the Python code for model training and testing, are publicly available. The trained models and the Python codes in this study provide a valuable resource that could have significant clinical applications for numerous types of cancer.
Sun, Anchen, Elizabeth J. Franzmann, Zhibin Chen, and Xiaodong Cai. "Deep contrastive learning for predicting cancer prognosis using gene expression values." Briefings in bioinformatics 25, no. 6 (2024): bbae544.
This work was supported by the Sylvester Comprehensive Cancer Center in partnership with the University of Miami College of Engineering under the Engineering Cancer Cures program Award Number SCCC-ECC-2022-01.

